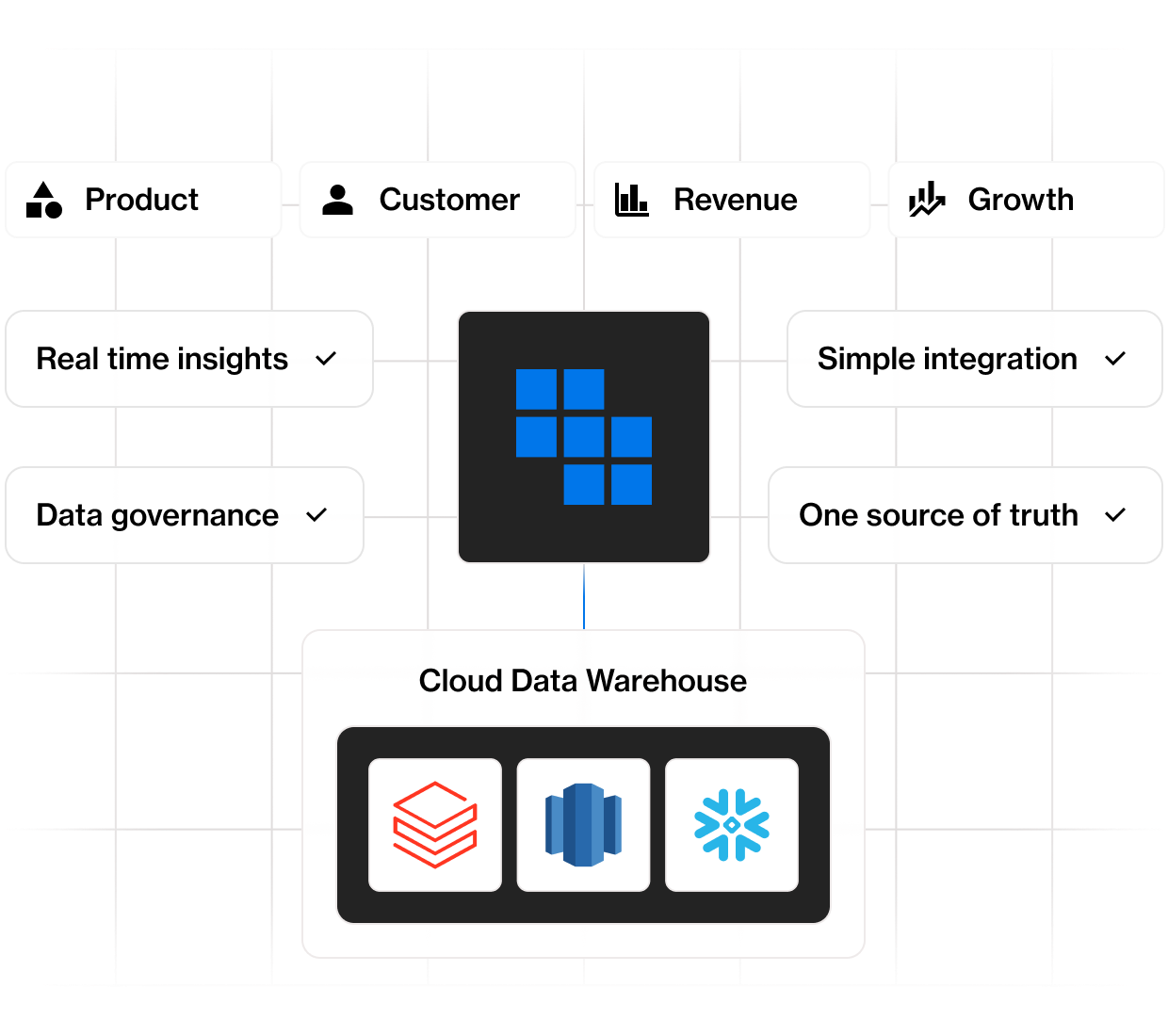
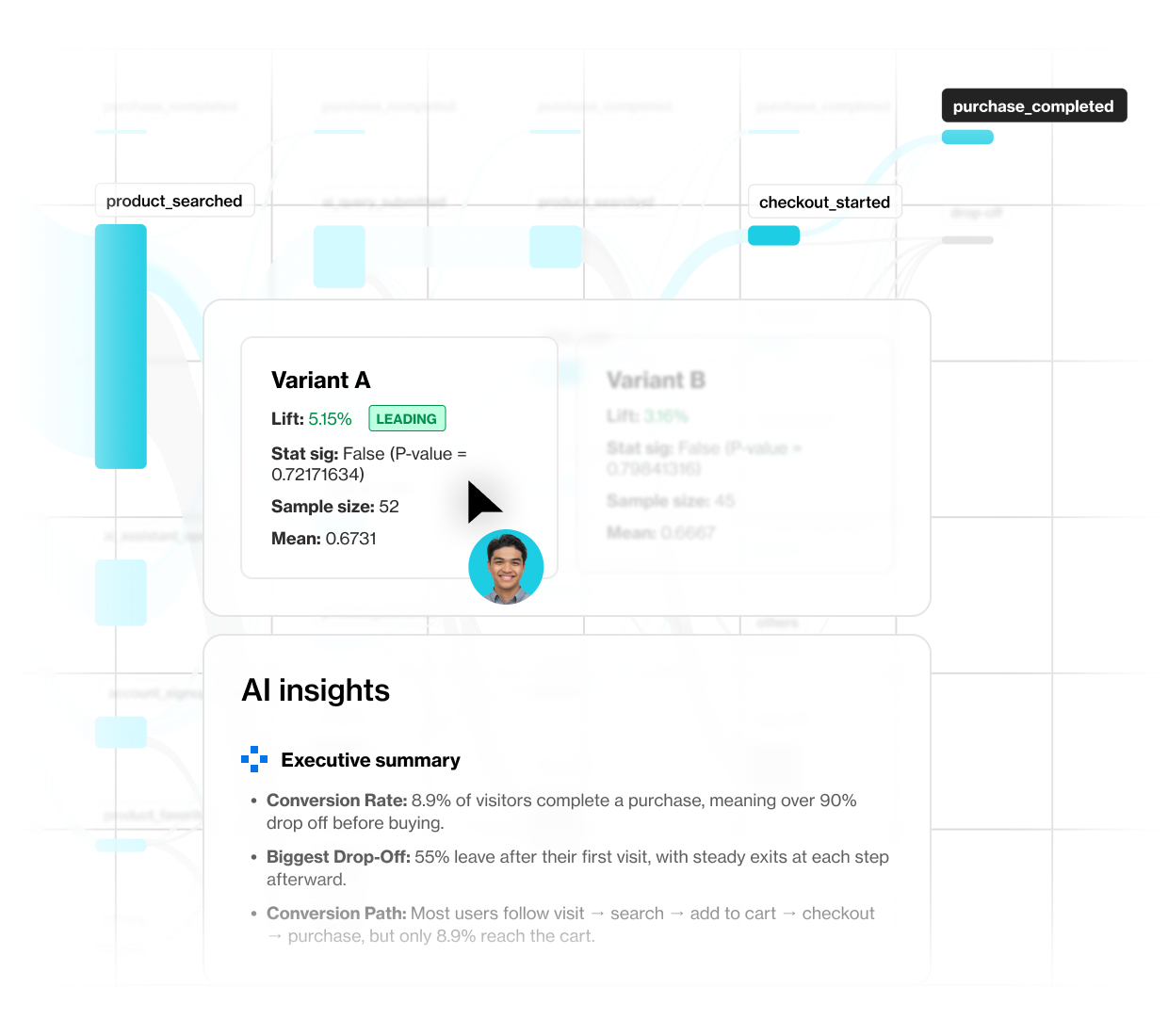
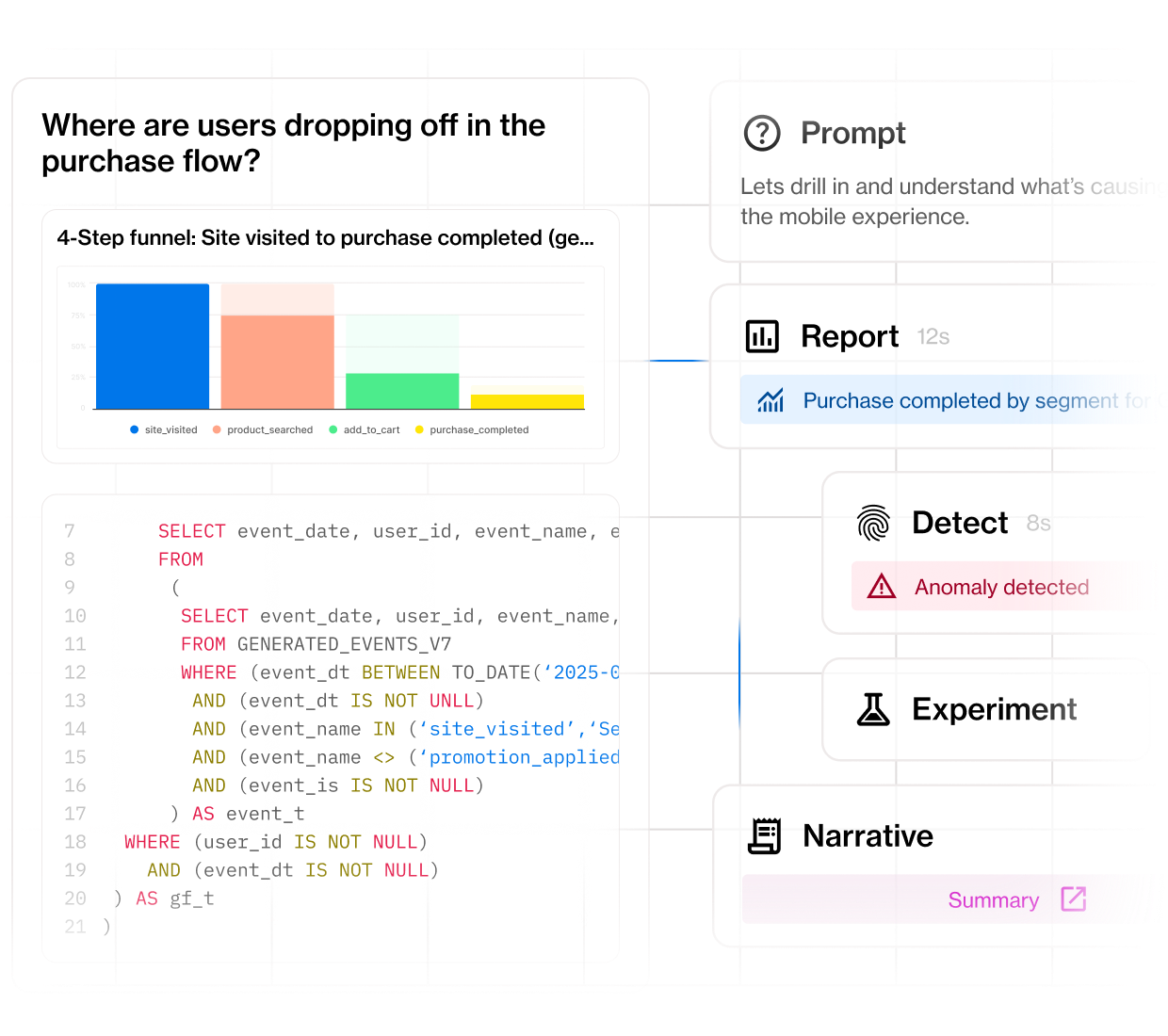
Eliminate the “data tax”
Legacy digital analytics have rigid integrations and pricing that quickly racks up costs. Kubit supports scale by removing the need for extra pipelines and redundant copies, plus offers unlimited anonymous users.
-
No event limits

-
No anonymous user limits
-
No ETLs
-
No reprocessing costs