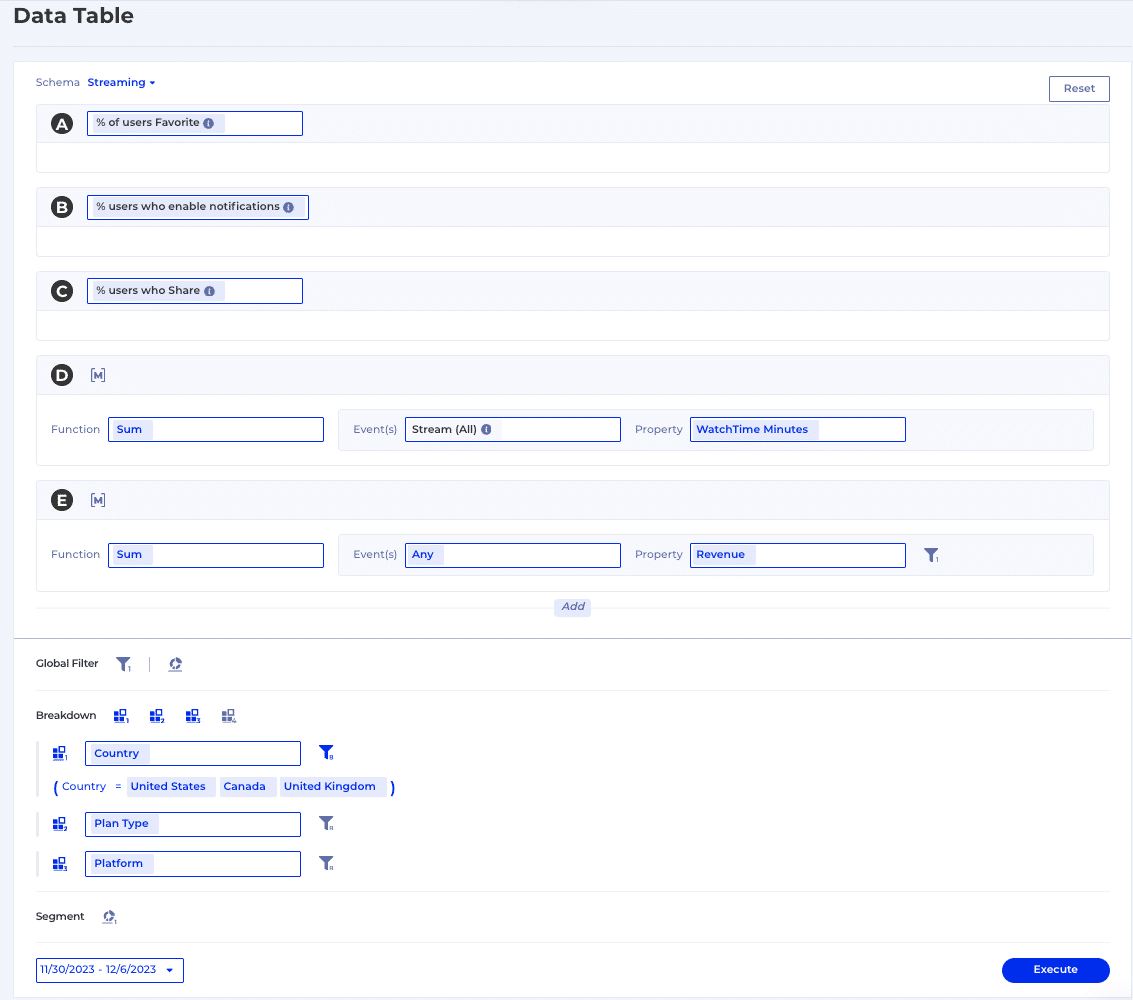
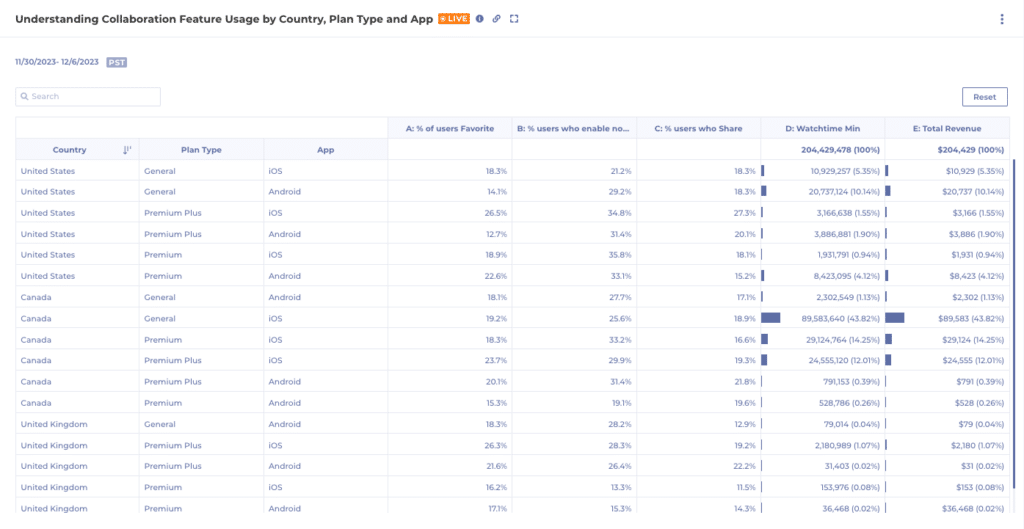
Warehouse-native Analytics for Content Team
Following the earlier blog “Unraveling the Truth Behind Warehouse-native Product Analytics”, let’s cover how the content team for digital products can effectively operate with integrity with this new approach in analytics.
What is Content Operations?
In streaming and entertainment applications, content plays a significant role in the engagement, retention and monetization since that’s everything customers interact with. It can also be used as a critical tool to attract new customers, drive conversion and reactivate dormant ones.
Though content typically is not free. There are licensing and loyalty considerations, also the cost to promote certain content to the right audience. For example, using a free show to acquire new customers or drive them to sign up for a trial subscription; or target a specific cohort of users with episodes from certain genres to bring them back to the platform.
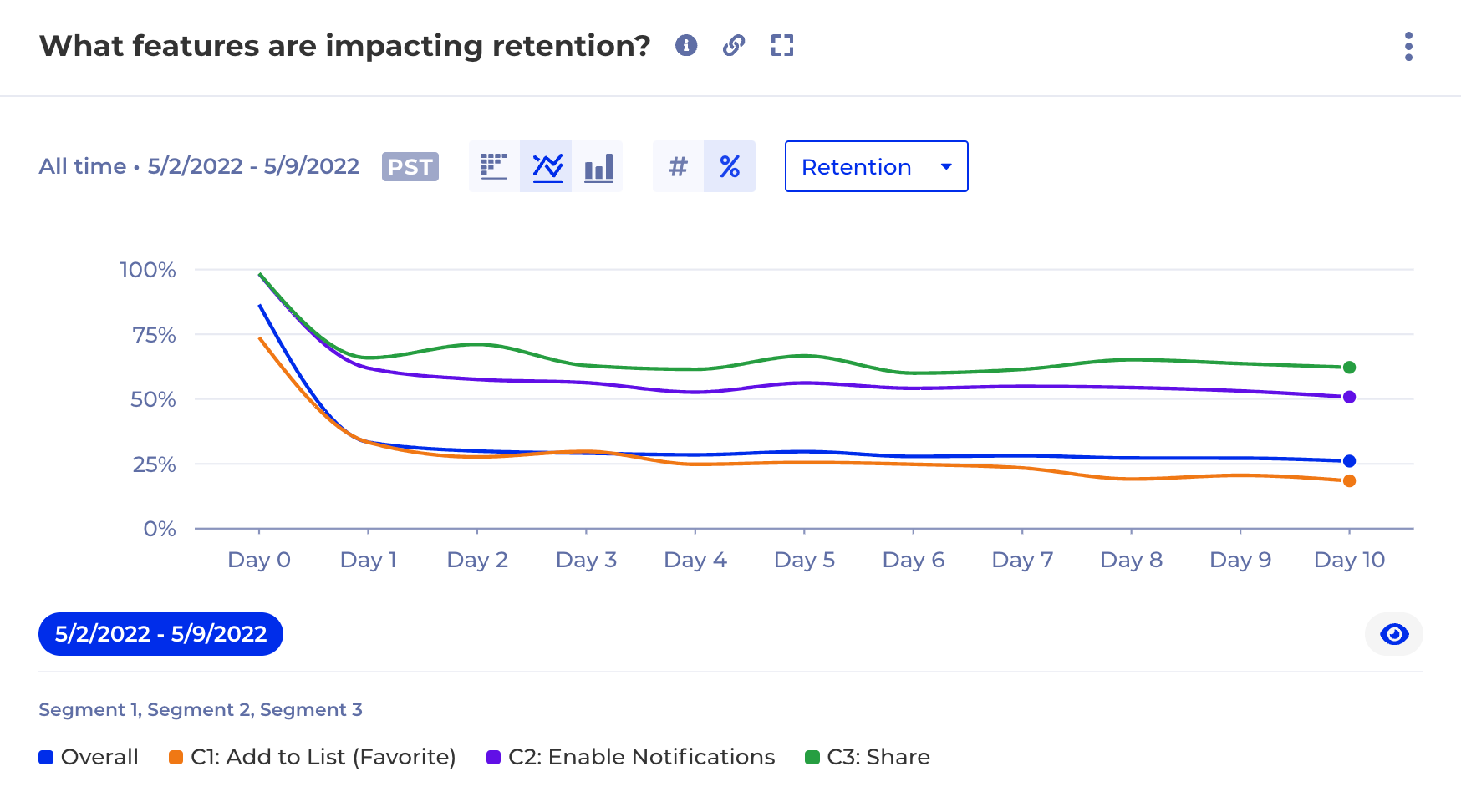
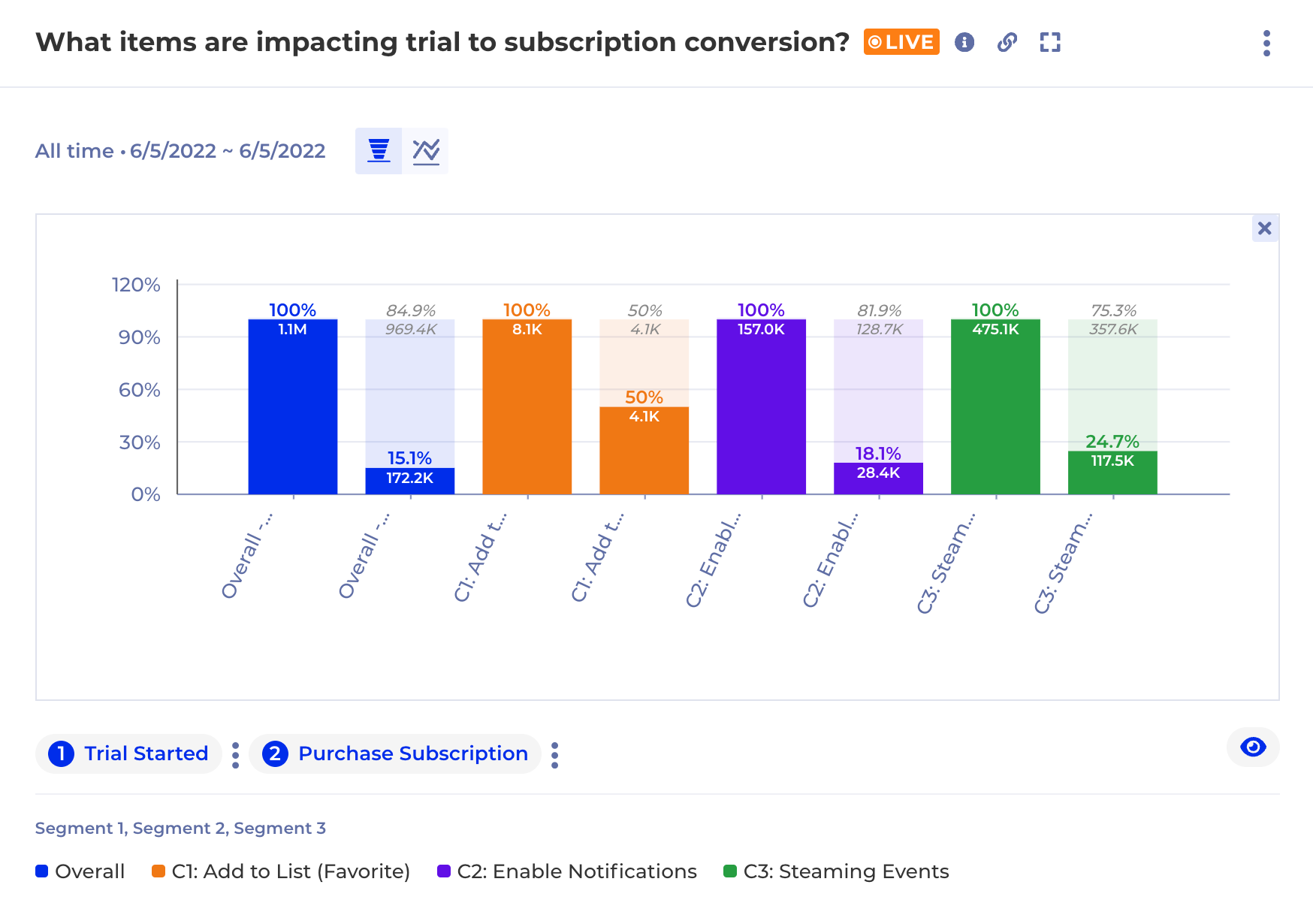
Even with sophisticated recommendation systems based on modern machine learning algorithms, the content team must conduct lots of experiments and measure their results to maximize the impact. It is a tricky balance since the audience’s taste changes frequently and can be easily influenced by the season or cultural atmosphere. That’s why content management becomes live operations.
Unfortunately, in most organizations, content analytics is typically overlooked and treated just as a reporting function and left for some pre-built reports to handle. Without self service and exploration, many enterprises couldn’t even connect the dots between content changes and long term customer behavior.
Complex Integration with Stale Data
Content data is massive and changes very frequently. Imagine a content database with every show and episode, with dynamic assignments to different channels, genres, carousels and promotions, along with confidential loyalty data. None of the information is available inside the digital application when a customer starts watching a video.
In order for these product analytics platforms to provide content insights, complex integration has to be completed to duplicate the content data into their data silos. Either the content data must be available inside the application on the devices, or special ETL jobs have to be built to sync it over periodically. Neither approach is ideal because of the dynamic nature of the content data itself: any kind of copying or syncing causes problems of stale data, or even worse, potential of wrong data.
There are also other vendors for each stage of a customer’s journey, like identity resolution, customer engagement and experimentation. The product analytics must have a copy of precious customer data from each and every vendor in order to deliver the insights. That is the root cause of all the headaches and issues.
There are criss-cross connections to be established through various approaches (e.g. ETL, API and storage sharing) and conduct heavy duty data copying. More often to anyone’s like, these connections can be broken, require maintenance, or even worse need to restate the historical data because of mistakes made. Just imagine the impact on the critical campaigns which require almost real-time insights.
Identity Resolution Becomes a Nightmare
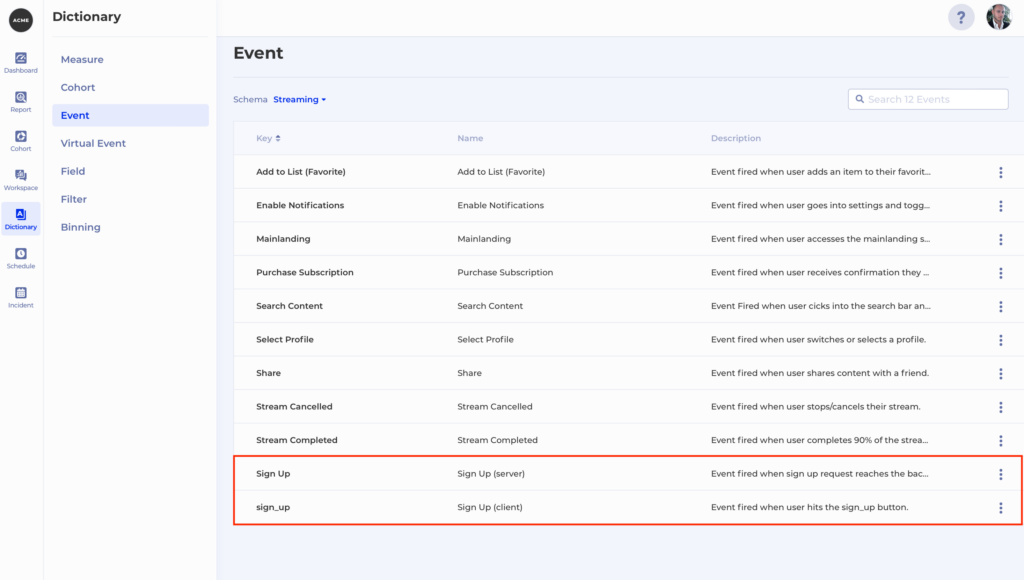
Streaming and entertainment apps are all very sensitive about data security and privacy. As required by GDPR like policies, most customer identifiers are obfuscated or anonymous and require identity resolution vendors (e.g. Amperity, LiveRamp) to stitch them together.
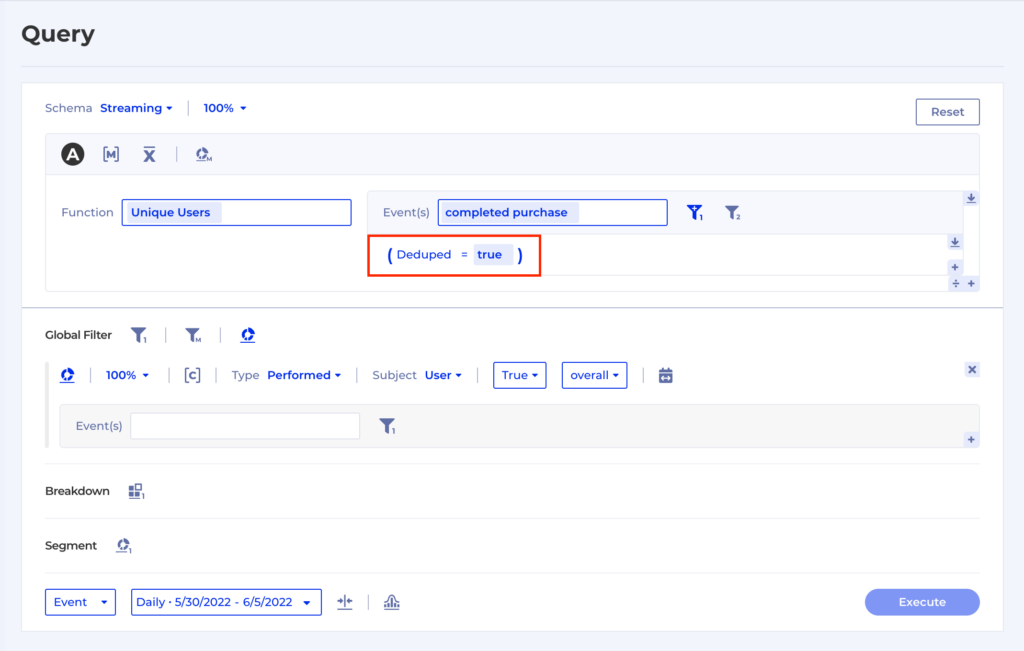
Unfortunately identity resolution is not deterministic and often there are desires to play/test with different strategies in order to measure certain content campaigns more accurately or efficiently. If the resolved ids have already been copied into product analytics platform’s data silos, there is no chance to restate or re-evaluate. Frankly, it is even hard to imagine how these insights can be trusted because technically as a third party, a product analytics platform shouldn’t store customers’ PII information in the first place.
No Single Source of Truth
This one is really simple: with copies of data lying outside of the enterprises, how can anyone trust the insights where the analytics platform is a blackbox and there is zero transparency to understand how the insights are generated. Needless to say, there is no reconcilability whatsoever. It would really take some vote for confidence to rely on these findings to make content decisions, which often involves millions of dollars of budget.
Limited View on Customer Impact
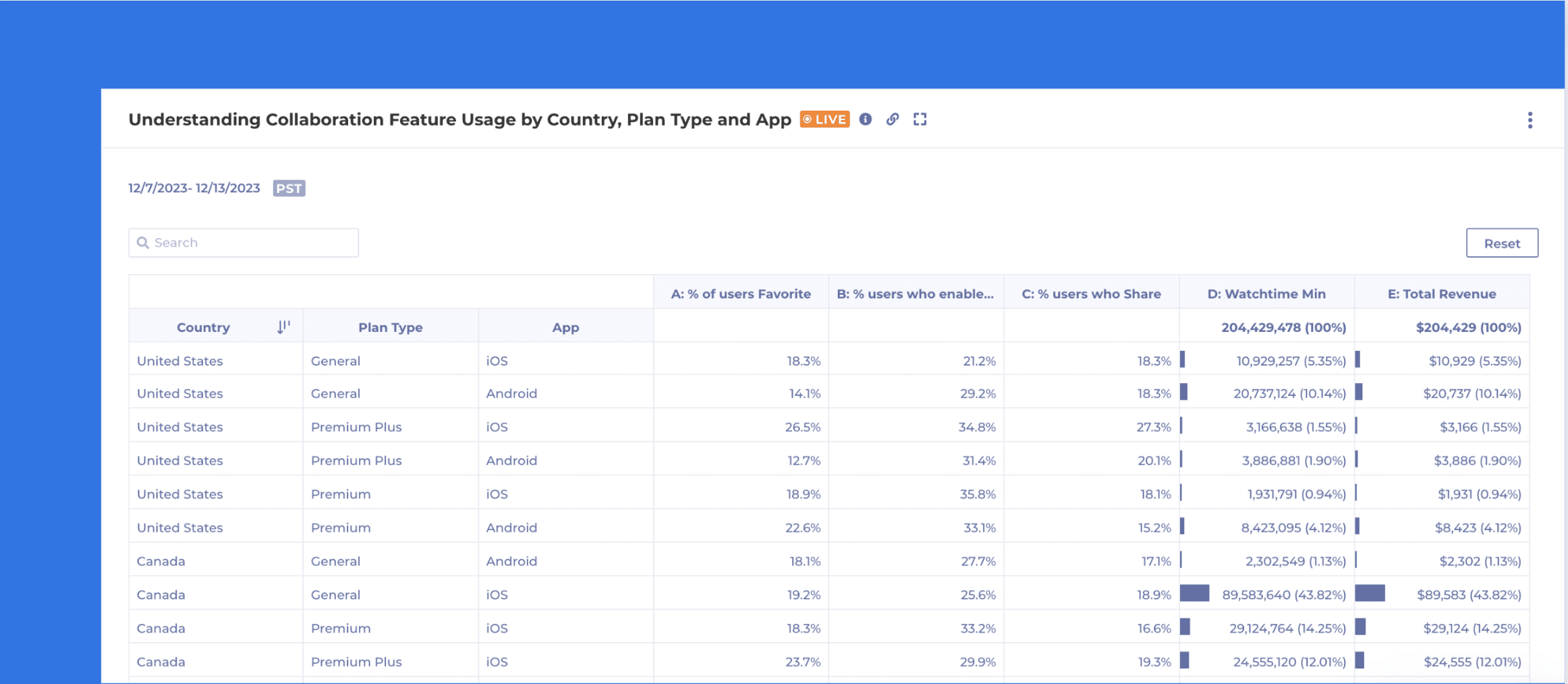
Because some content data (like loyalty) is too sensitive to be sent to the digital app or the third party analytics vendor, some changes very fast and require constant restating or backfilling (like cataloging information), there can never be a complete 360 view of customer journey with siloed product analytics.
In addition, most media apps generate significant amounts of behavior data, like heartbeat events for video watching, which would lead to skyrocketing cost on such platforms which typically charge by data volume because they ingest customer data. Many content teams were forced to sample their data and live with partial insights which could lead to completely wrong results.
The Warehouse-native Way
All of these problems can be solved with the warehouse-native approach when the enterprise is committed to have full control of their data within a cloud data warehouse. By bringing all of the clickstream, identity resolution, impression, conversion and A/B test data from the vendors together and making their own data warehouse the Single Source of Truth, new generation of warehouse-native analytics platforms can connect directly to customer’s complete data model through effortless integration and ensuring both the integrity and self service perspectives required by content operations.
Effortless Data Integration
For the enterprise, they just need to collect their own customer data (including clickstream/behavior, content and operational data) and all vendors’ data into a central data warehouse which is under their full control. Often, access to vendors’ data can be achieved through Data Sharing protocols (available in most cloud data warehouses) instead of duplication with ETL or API.
There is no complex graph of data flow outside of the enterprise, especially between vendors. When there are data issues, only one place needs to be fixed and it is easily verifiable instead of coordinating with several third parties to pray that they will do the right thing since there is no visibility into their black boxes. There is no data backfilling, scrubbing or restating required.
Flexible Identify Resolution
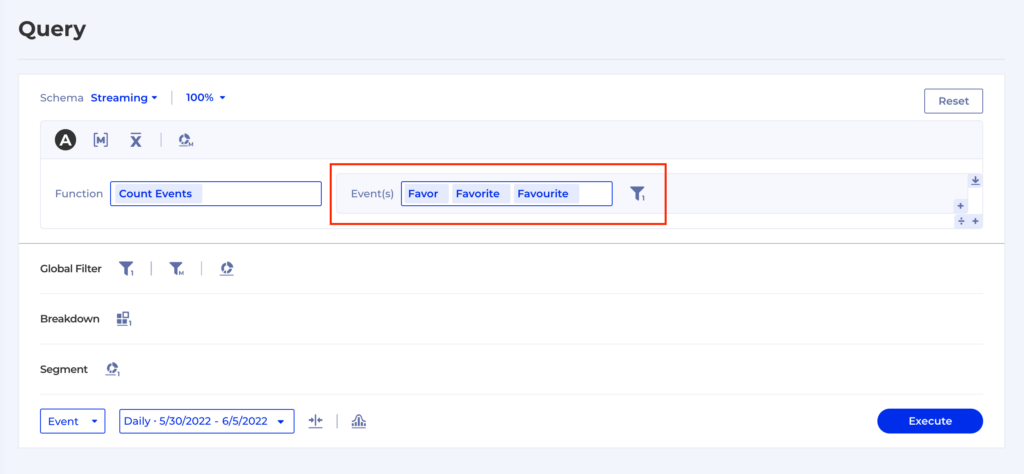
Because all the data now goes to the enterprises where the customers are from, all available customer identifiers can be explicitly stated and used for analytics internally without the need for hashing and complicated matching (often guessing) algorithms.
Even better, the content team can experiment different identity resolution or attribution strategies on the fly, without the need to engage with vendors or reprocess any data. The ability of asking and validating “what if” questions before commitment gives complete confidence and flexibility.
Moreover, sensitive identity data can also be hidden or dynamically masked for warehouse-native analytics platform’s access since they don’t need to see the individual data as long as the underlying join works.
Exploration with Integrity
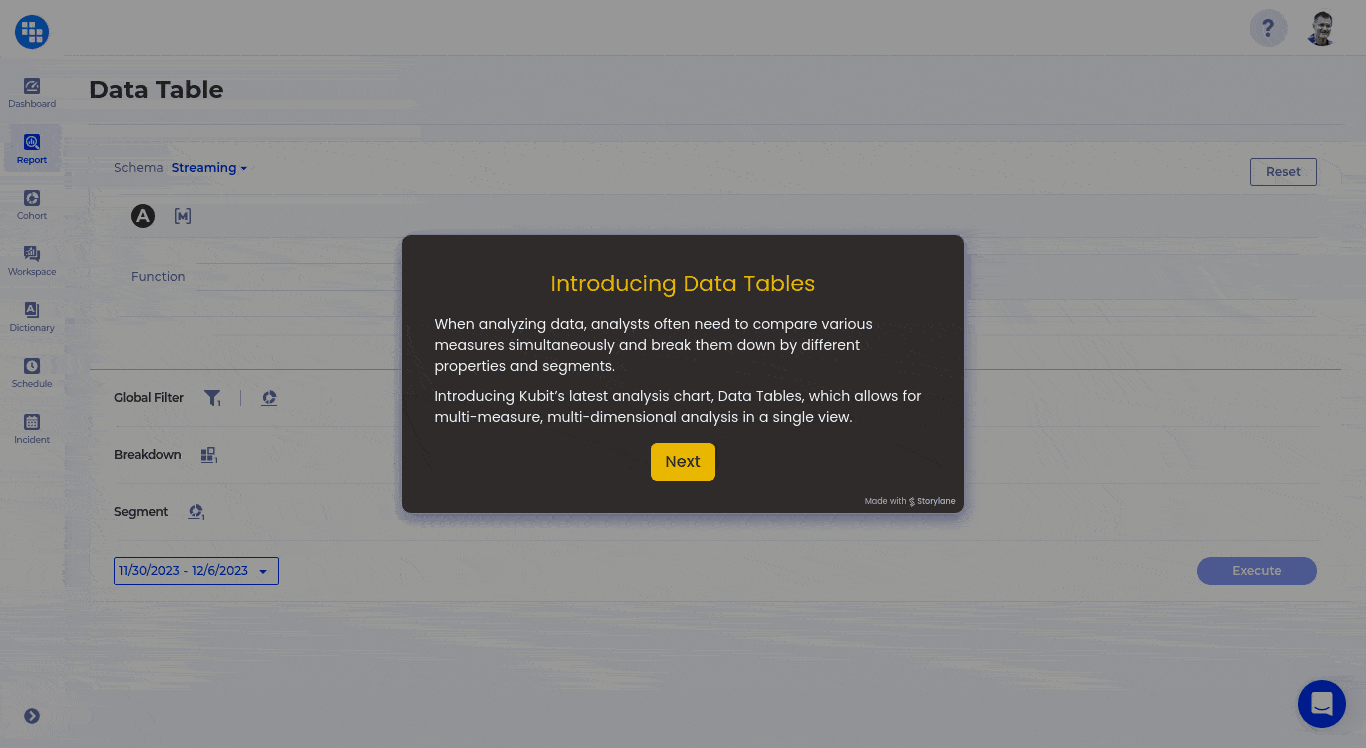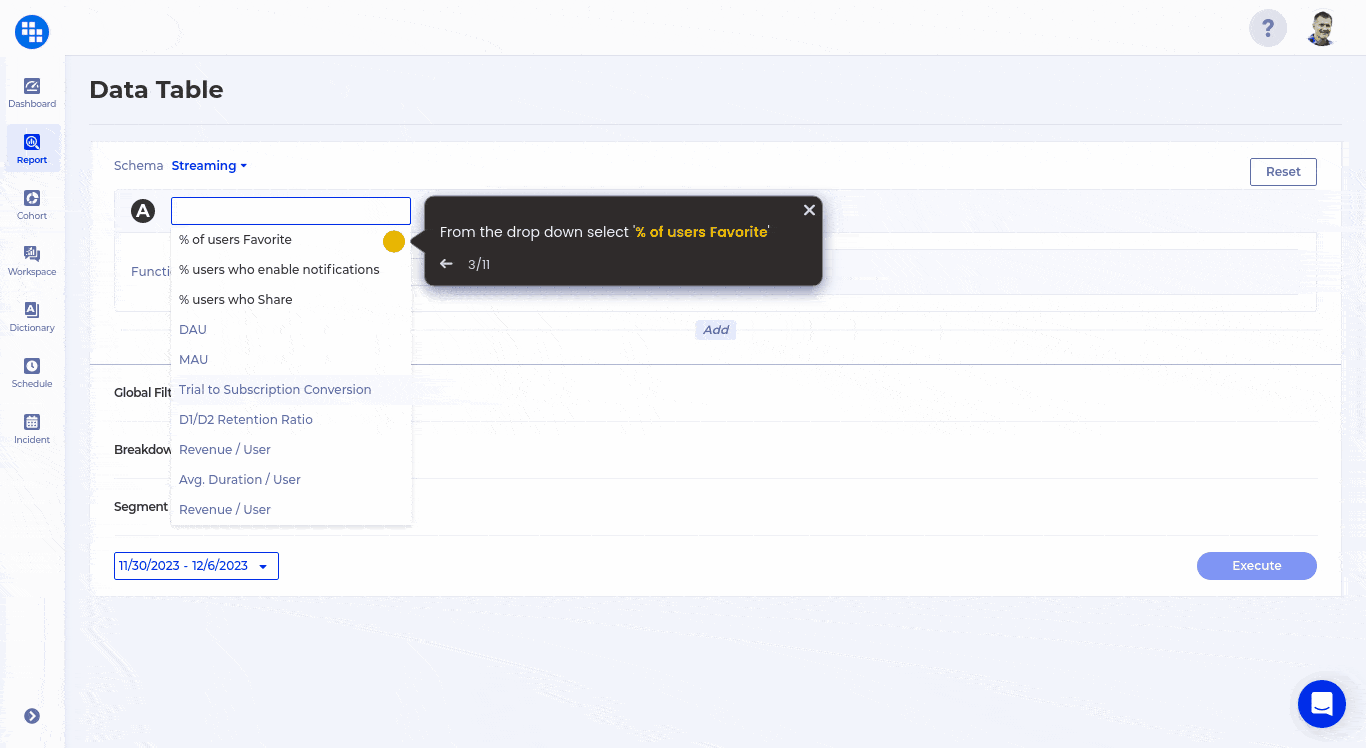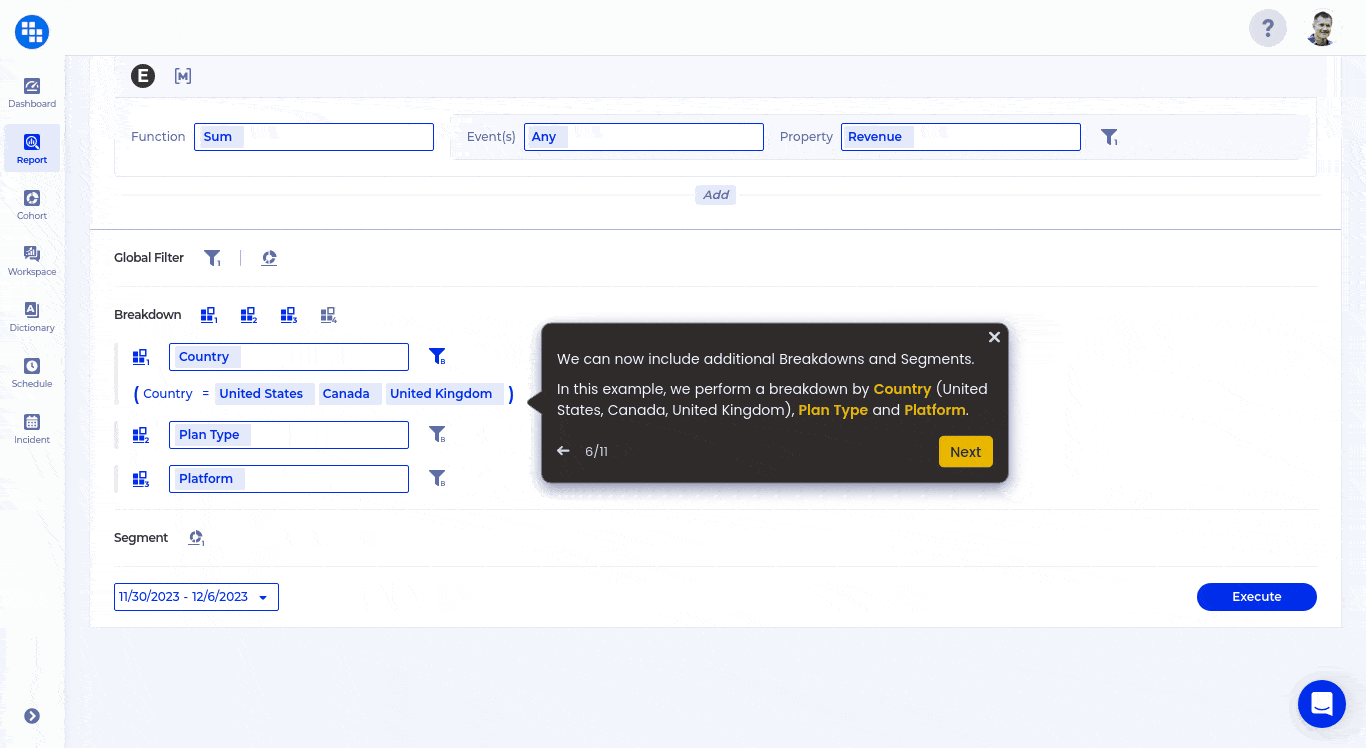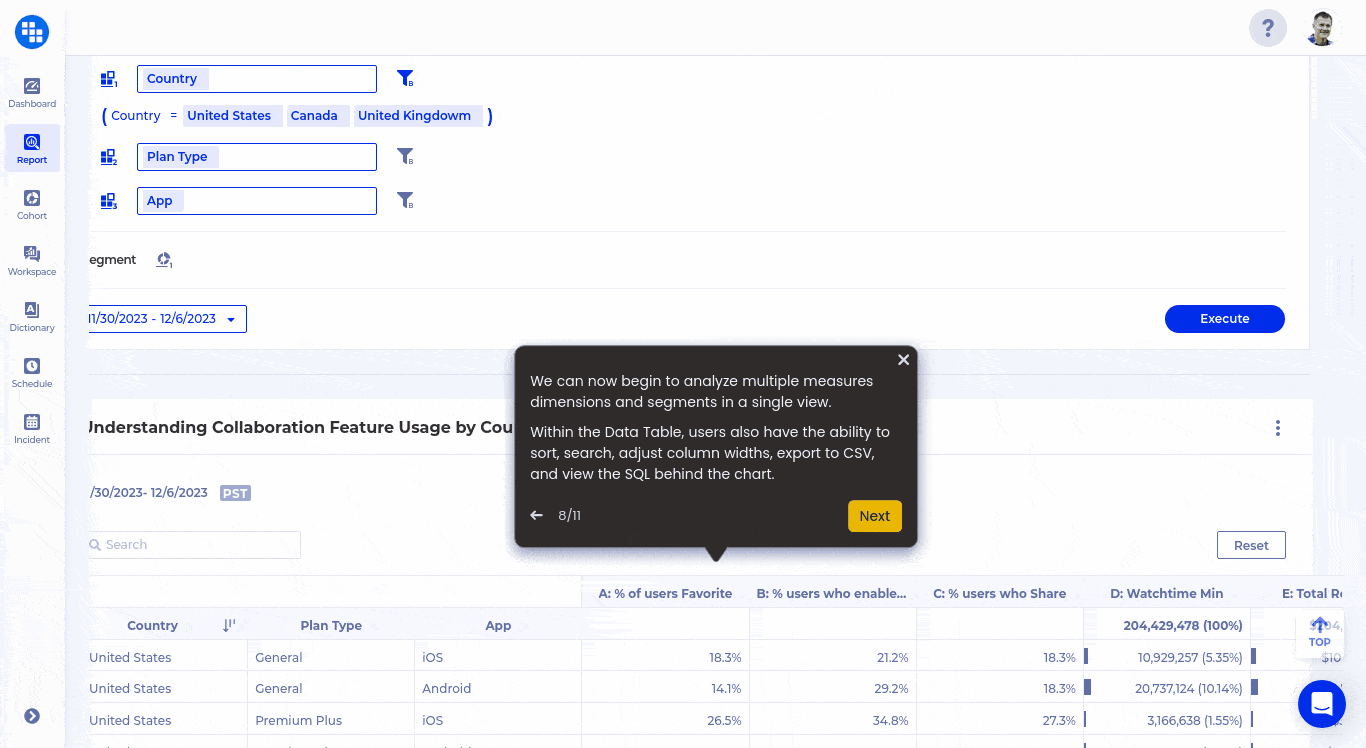
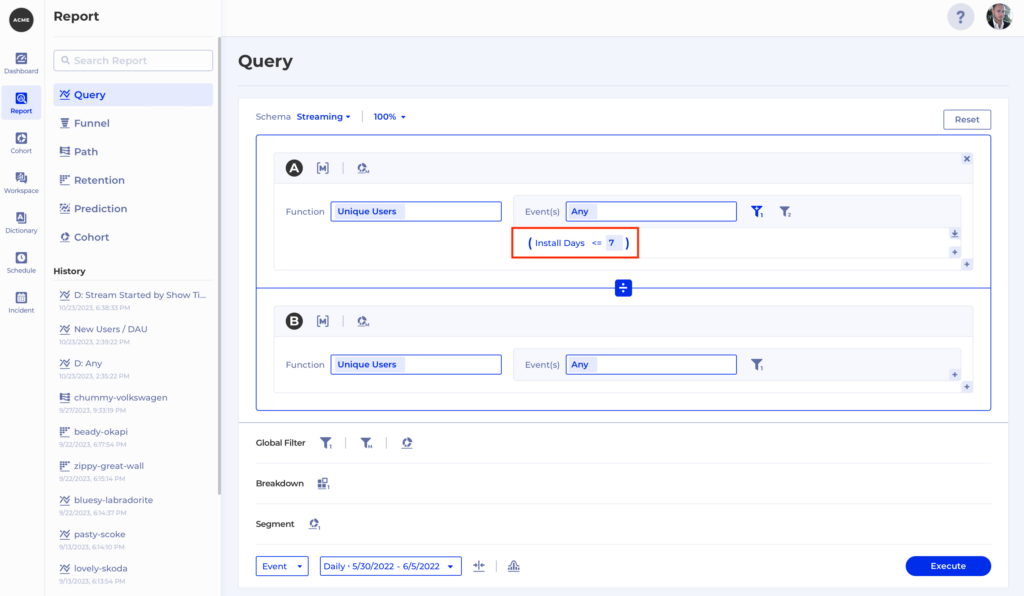
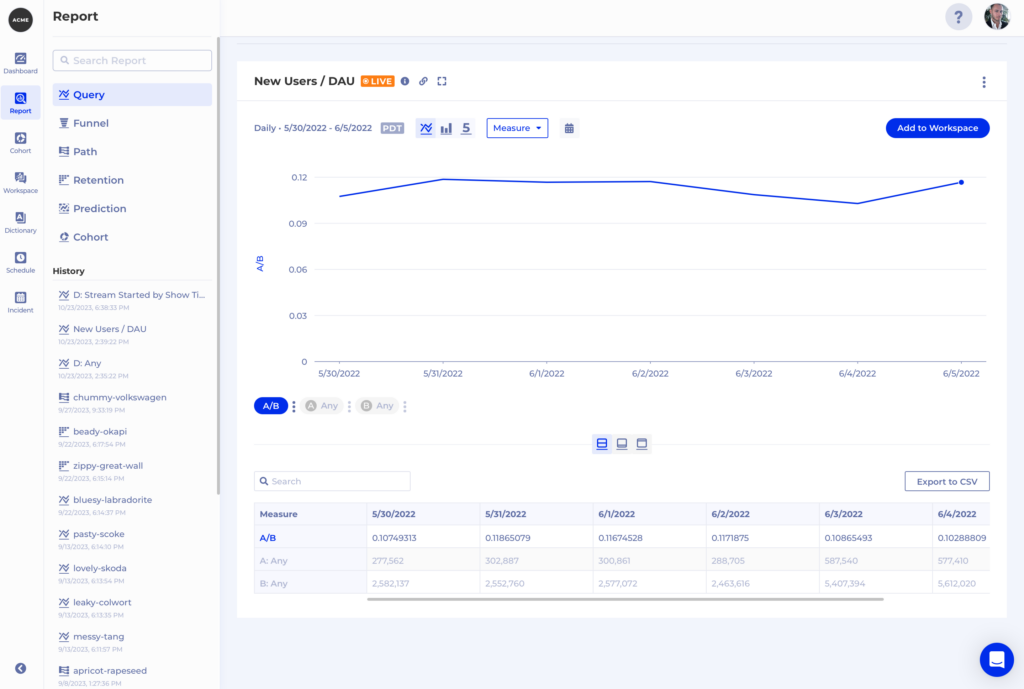
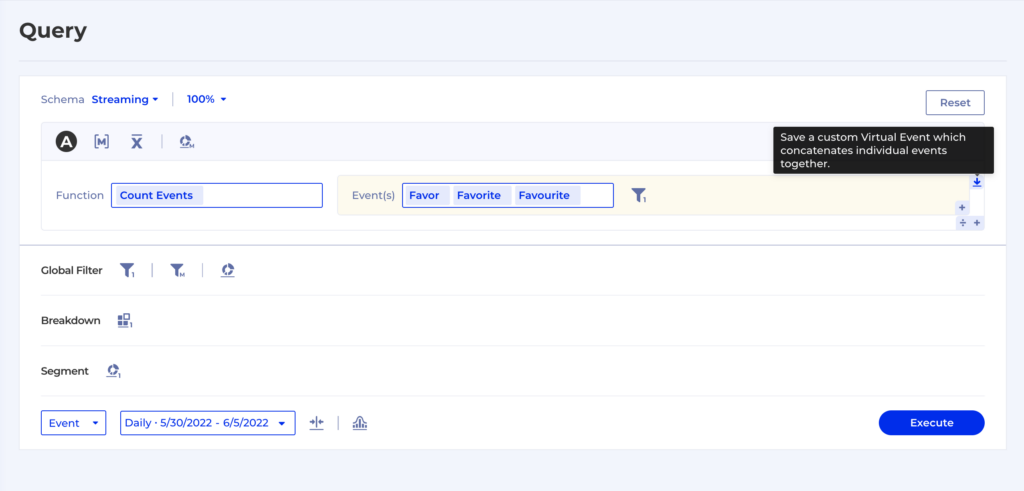
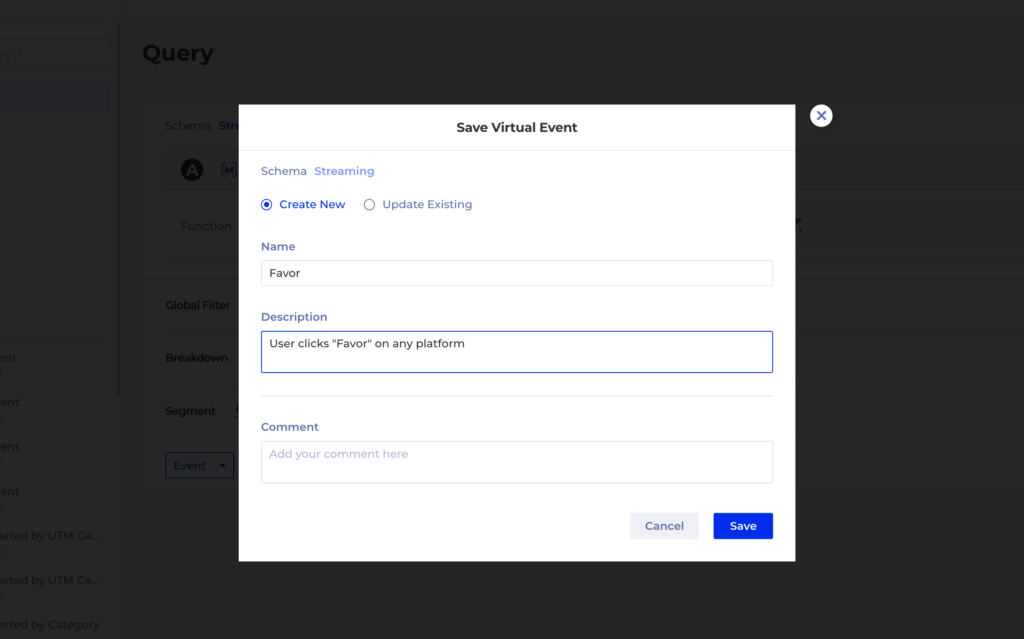
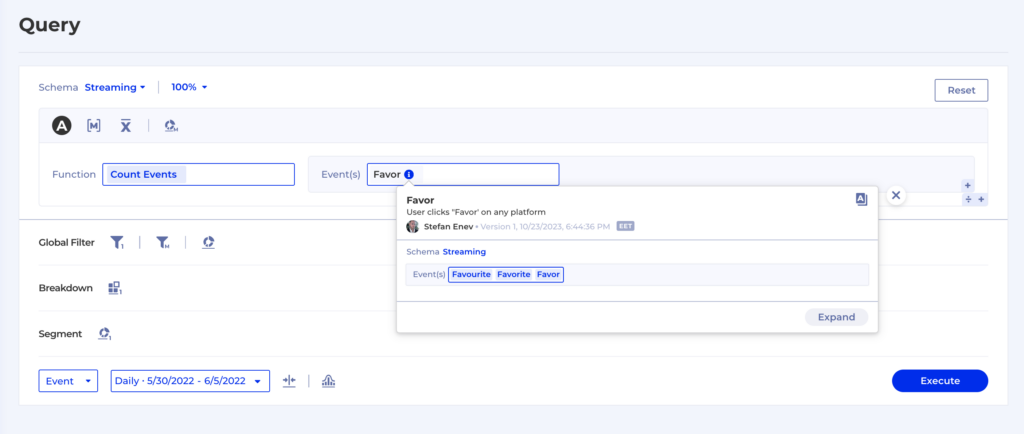
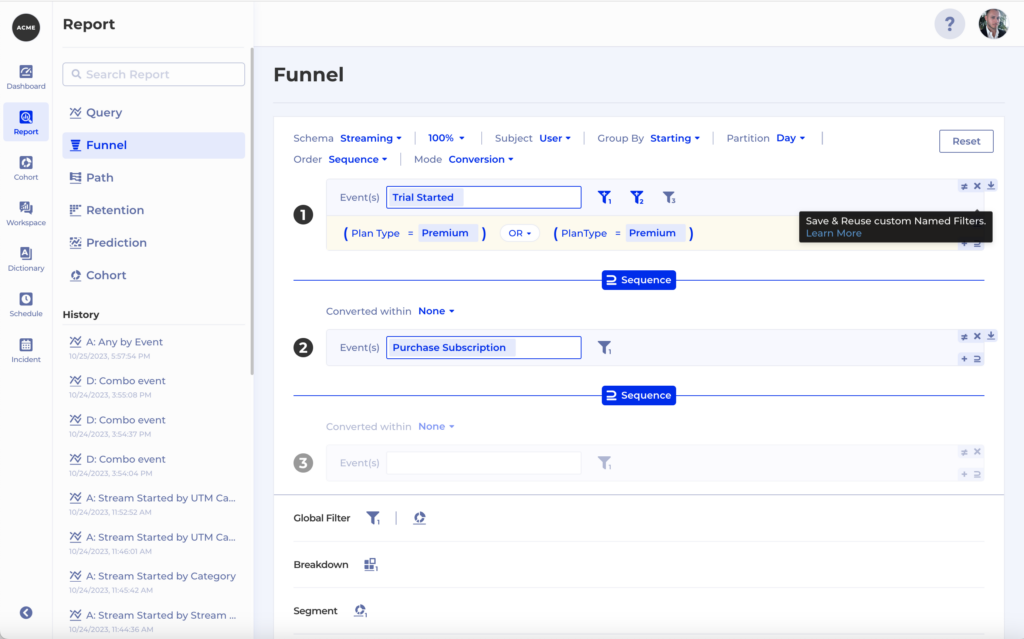
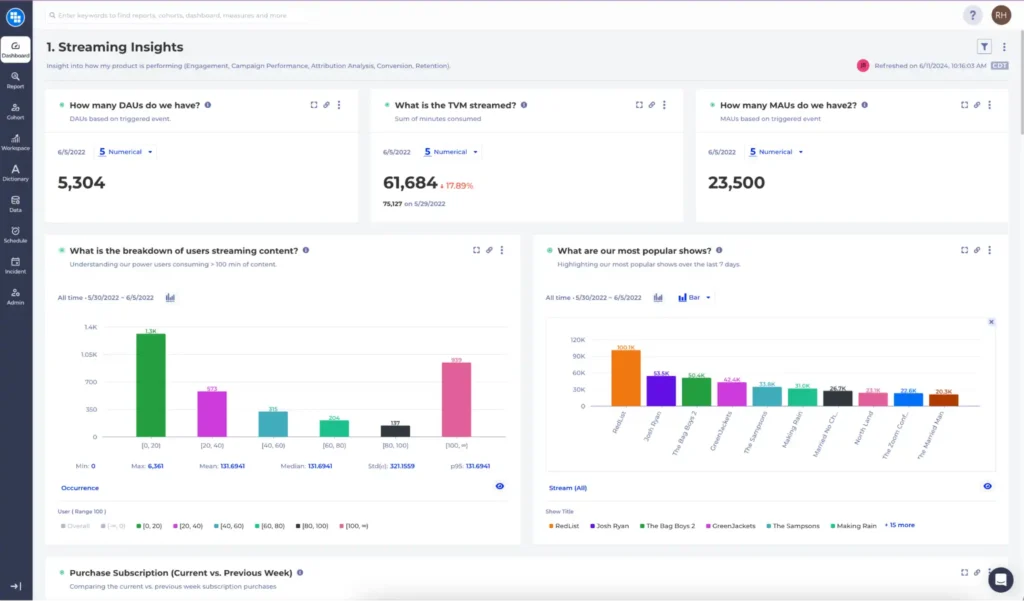
With One Single Source of Truth, and the ability to provide the SQLs behind every insight, the content team can now measure their content impact, explore customer insights in a self service manner while maintaining the highest level of integrity. There are never concerns about data volume or bringing in new data for analysis.
The transparency delivered by warehouse-native analytics makes it complimentary to any other BI, AI or machine learning tools, where they can not only reconcile the insights but also build on top of them. For example, a complex subscription retention analysis for different content cohorts can now be embedded into the machine learning algorithm for content recommendation as the KPI for the tuning purposes because the SQL is fully accessible.
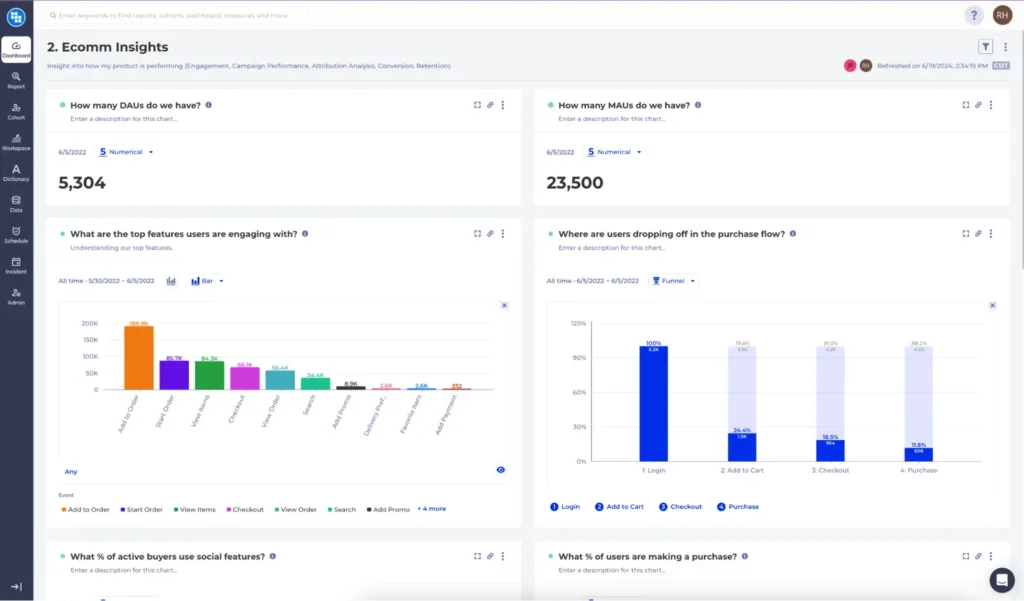
Full Customer 360 View
With all the data about customers’ complete lifecycle stored in one place. warehouse-native analytics can easily analyze the impact from content campaigns with subscriptions, lifetime value, retention and reengagement data. Best yet, because all insights are generated dynamically, there are no ETL jobs to develop, no data to backfill when new data is required. That means that growth marketers don’t have to wait weeks or months for some data model changes required for specific vendors. Live customer insights with thorough depth is not a dream any more.
Summary
The days of data silos are long gone. With the convenience and advantages, warehouse-native analytics for content operations is an undeniable trend for enterprises with media and entertainment focused digital products. Getting reliable, trustworthy insights from a Single Source of Truth should be on the top of the mind for every serious content team.