
Intro
We already know the perfect data model for product analytics but even with a perfect data model you can get tripped by other data issues on your way to obtaining insights. It often happens that a data issue is uncovered while working on a report in Kubit and it suddenly blocks the task at hand. Unfortunately, data issues typically take time to fix – in the best case scenario as early as the next sprint, often a month or two and in some rare cases the issue cannot be resolved at all. So while at Kubit we advocate for data modeling and data governance best practices, we have also developed a few features to help you work around 5 typical data issues in a self-service fashion while the root cause is being addressed:
- Missing Data
- Duplicate Data
- Ambiguous Data
- Inconsistent Data
- Too Much Data
In this blog post we’ll explore how you can leverage these features to save the day whenever a data issue tries to stop you from getting your work done!
1. Incomplete Data
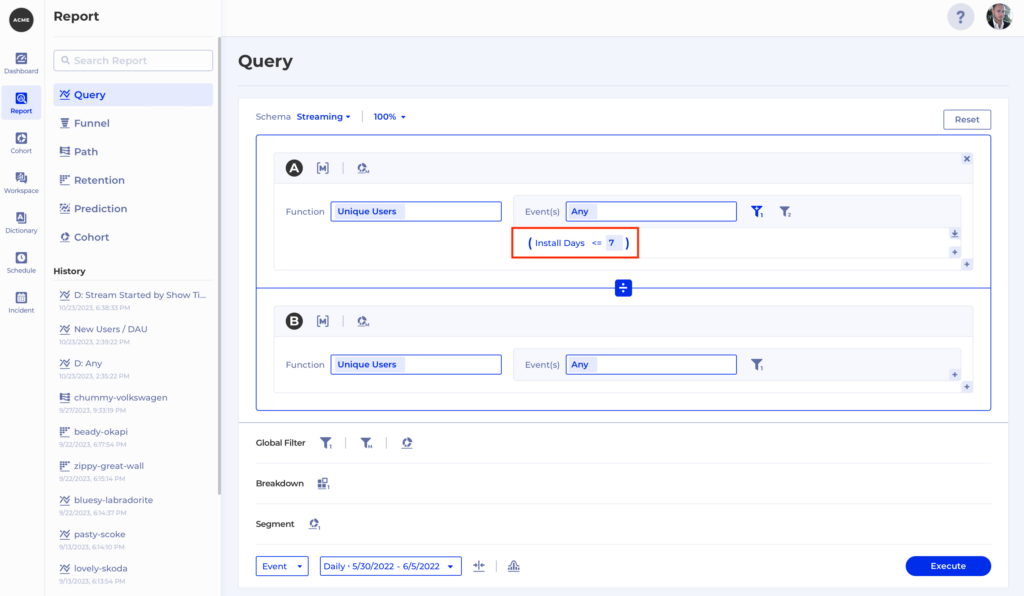
Very often we have some building blocks in our data but we don’t quite have the value we want to filter by. For example, we may have a timestamp property generated when a user installs our app, but for our report we want to measure the percentage of daily active users who installed our app within 7 days. Or we might want to filter by session duration but this information is not available when each event is triggered and must be computed afterwards. Or we may even want to extract the user’s device platform from a user-agent header.
Whenever this is the case you can reach out to the Kubit team to define what we call a “virtual property” which will be computed on the fly on top of your existing data. To continue our first example, let’s call the virtual property Install Days and it will be based on a timestamp column named install_date. Now we can think of our virtual property in SQL like this:
datediff(day,install_date,event_date)
However, it looks like and is used as any other property within Kubit which makes our analysis very simple – we get the amount of unique users who are active and filter by Install Days <= 7, then divide that by the total number of daily active users like this:
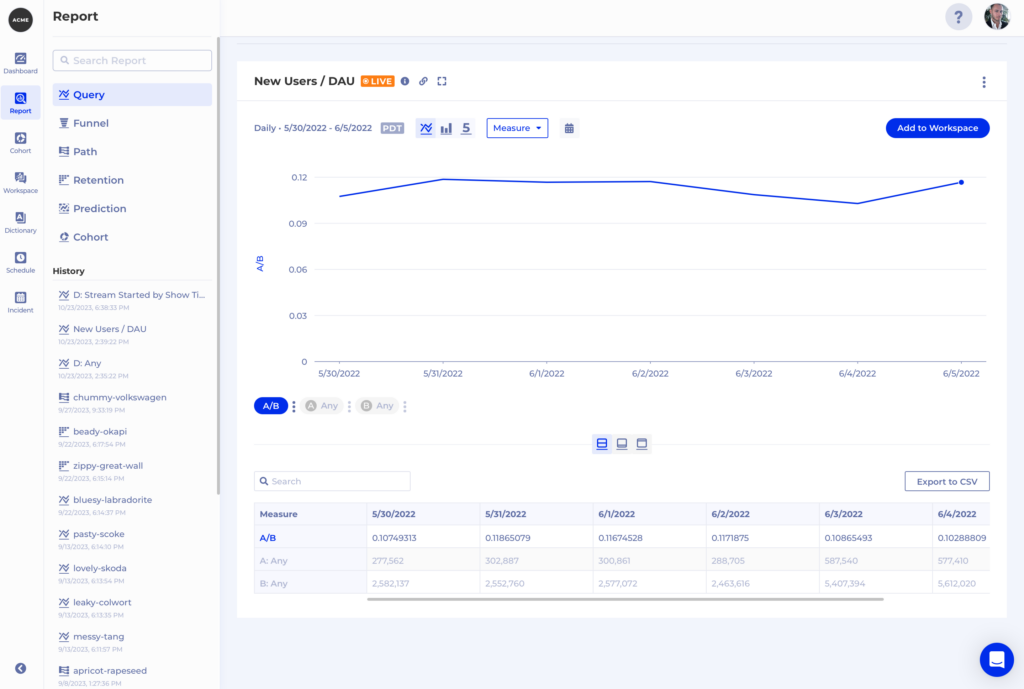
2. Duplicate Data
Duplicate Data is always a pain to deal with and in the context of product insights we usually see it in the form of duplicate events. You can already leverage Kubit’s zero-ETL integration to do as much data scrubbing as you need. The results of your work will be immediately available in Kubit without any extra effort required. However, we often get asked to try and resolve some duplication on the fly – maybe the team who can fix the issue is overloaded, or there is some third-party responsible for the events generation – in both cases the process to resolve the issue will take any time between a lot and never.
Again, “virtual property” can come to the rescue, as we can generate a virtual property based on some criteria on only one of a set of duplicate events so we can distinguish it from the rest. Let’s consider the following example – imagine we have 5 purchase events for the same user, all for the same purchase but at different timestamps:
user_id | event_name | purchase_id | event_date | purchase_amount |
|---|---|---|---|---|
a7cb92df1c87c07fd | completed purchase | 20041876 | 2023-10-23 15:23:11 | $18.78 |
a7cb92df1c87c07fd | completed purchase | 20041876 | 2023-10-23 17:05:47 | $18.78 |
a7cb92df1c87c07fd | completed purchase | 20041876 | 2023-10-24 10:32:03 | $18.78 |
a7cb92df1c87c07fd | completed purchase | 20041876 | 2023-10-25 22:11:59 | $18.78 |
In this case, if we want to find the number of unique users who made a purchase, the duplication is not really a problem. But if we want to count the number of purchase events or aggregate the purchase_amounts, then our results will be way off.
How does Kubit fix this?
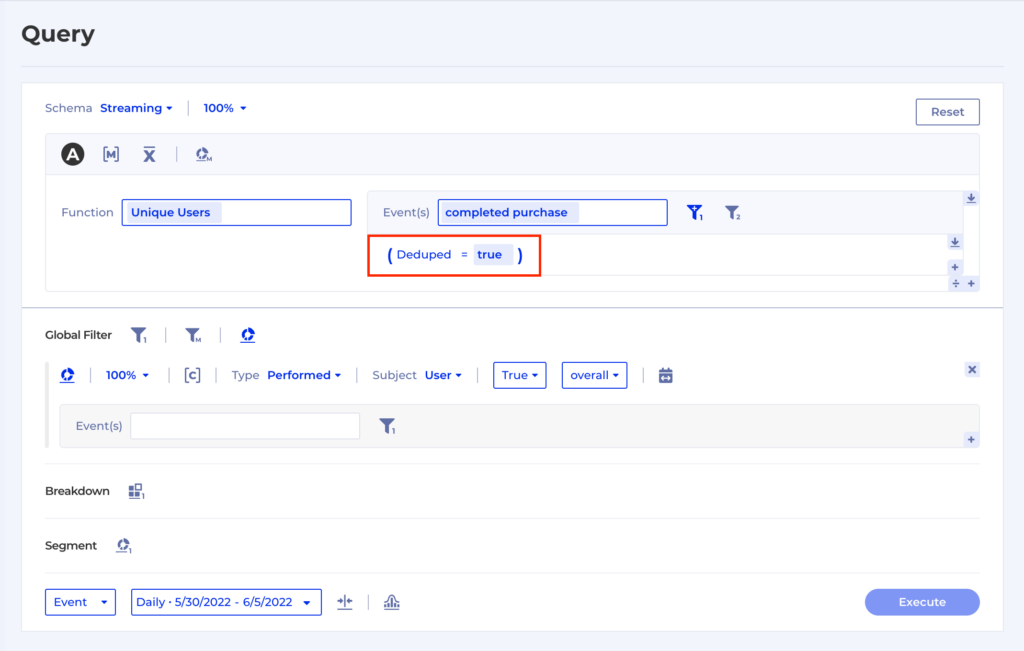
We can advise on the best solution, but one example is to assign a boolean property Deduped with a value true on the first of a sequence of duplicate events. Kubit can easily select the first duplicate event in a time range using some SQL along those lines:
CASE row_number = 1 ROW_NUMBER() OVER(PARTITION BY user_id, purchase_id ORDER BY event_date ASC NULLS LAST) AS row_number
And once we have the first event of the sequence we can assign the virtual property. So now we can aggregate without any adverse effects caused by the event duplication:
3. Ambiguous Data
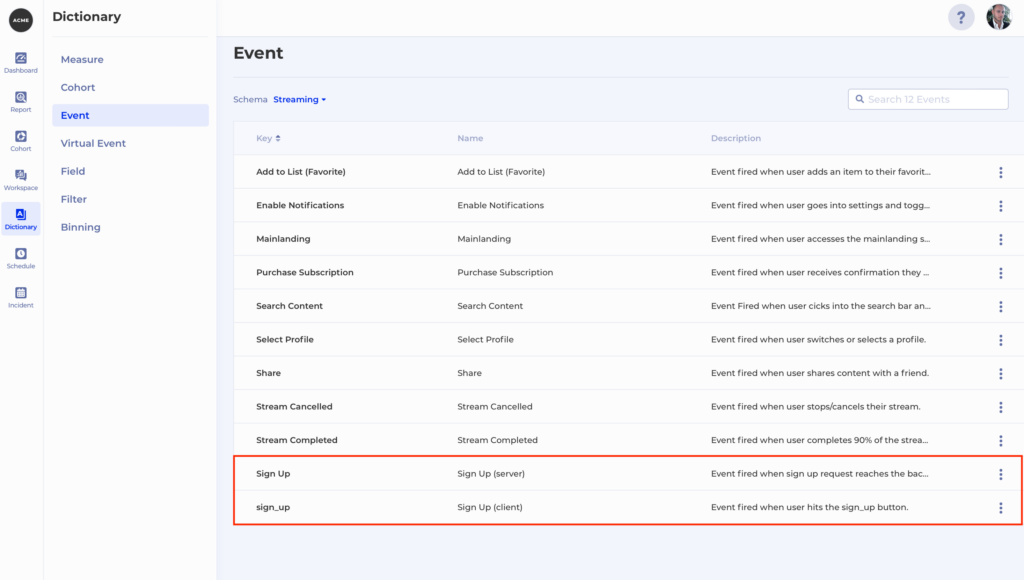
What if 2 events in our dataset are easy to confuse with one another? Perhaps the naming is not ideal and people often make mistakes when they need to use them for a report. Let’s say we see 2 Signup events in Kubit – Sign Up and sign_up.
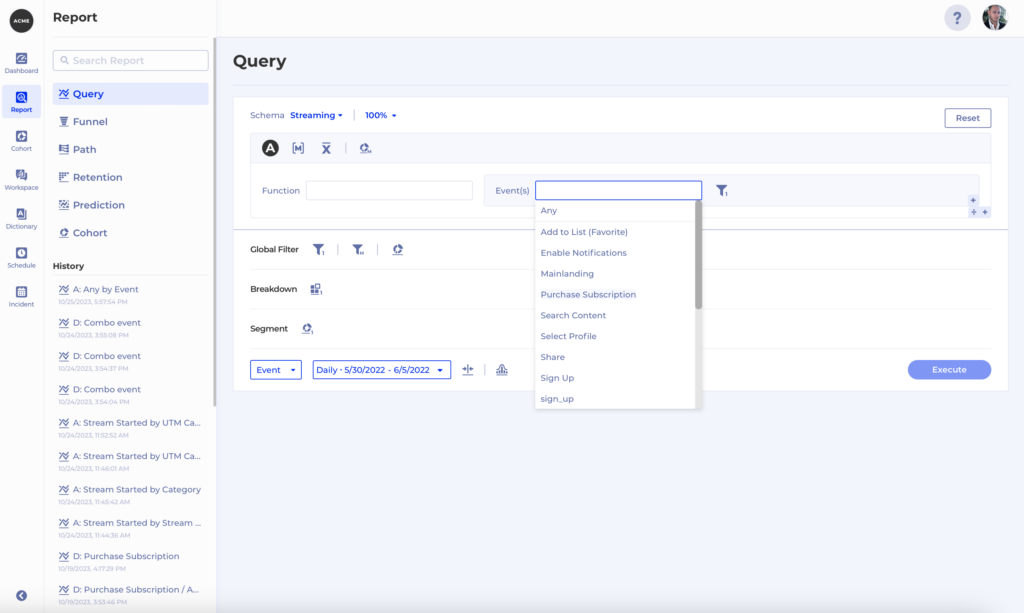
But what is the difference between the two? Maybe one is a front-end event and the other is a back-end event, but the names don’t reflect that. There is a quick fix you can make yourself in Kubit to make the difference between the two events much clearer. You can simply go to Dictionary -> Event and Rename from the Context menu for both events to give them more appropriate names, e.g. Sign Up (server) and Sign Up (client), and a nice description:
4. Inconsistent Data
This is true especially for multi-platform apps. As soon as you start instrumenting on multiple platforms inevitably from time to time there will be discrepancies between the implementations which can result in any of the following issues:
- the same event comes back with a different name from one or more platforms
- property name is different on one or more platforms compared to the others
- a property value mismatch between platforms
4.1 Same event, different name
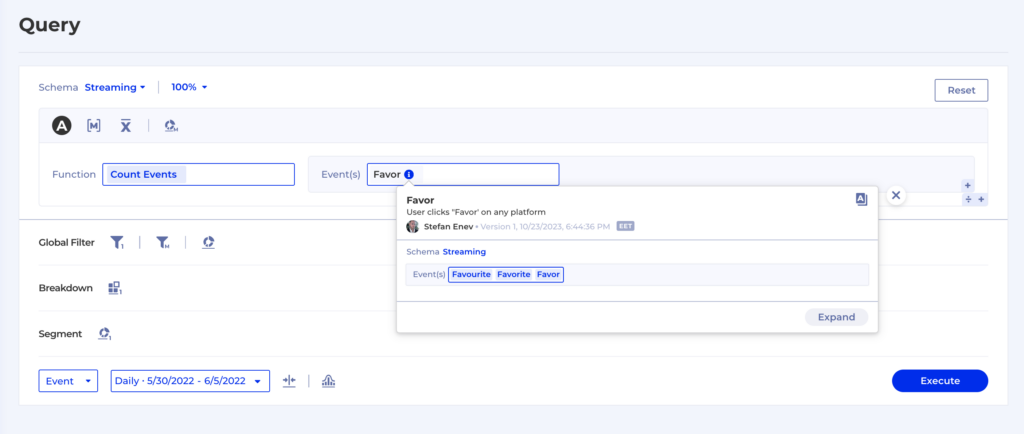
Let’s say we have the same event coming back from different platforms in 3 different flavors – Favor, Favourites and Favorites.
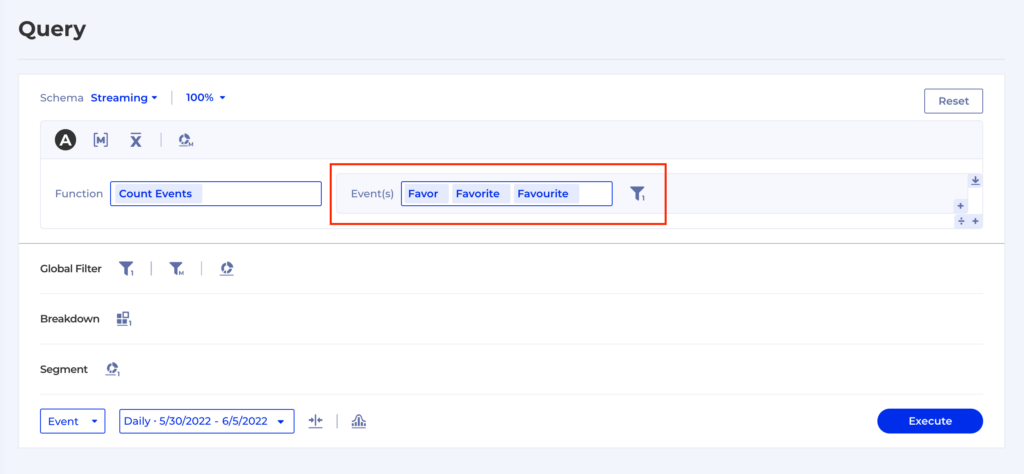
Such a situation can be extremely frustrating as you now have to go talk to multiple teams responsible for each instrumentation, align with their release schedules, prioritize the fix and wait for it to go live so you can go back and finish your work. This is one of the reasons why we developed Virtual Events as a way to group and filter raw level events to create new entities which have exactly the meaning we want them to.
It’s super easy to create a Virtual Event, anywhere in Kubit where you have an Event Group an a Filter you can save that combination like this:
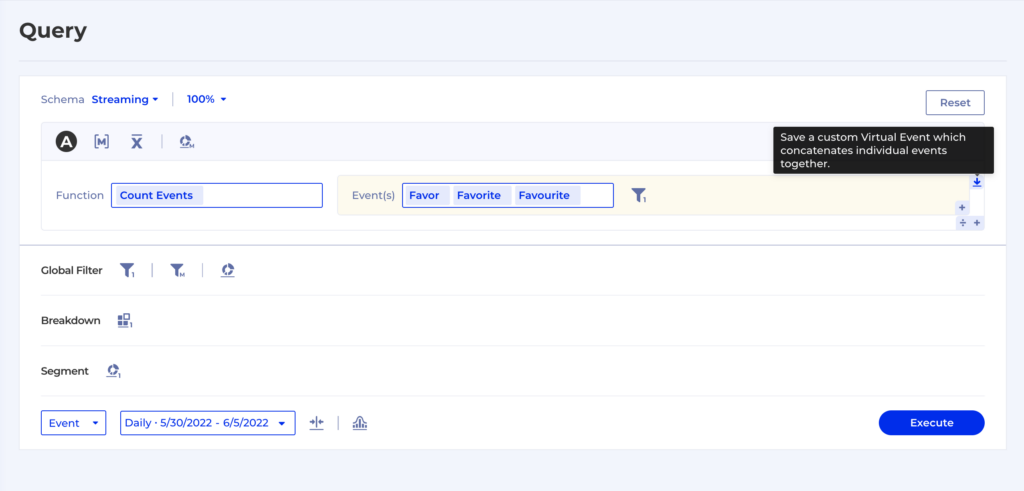
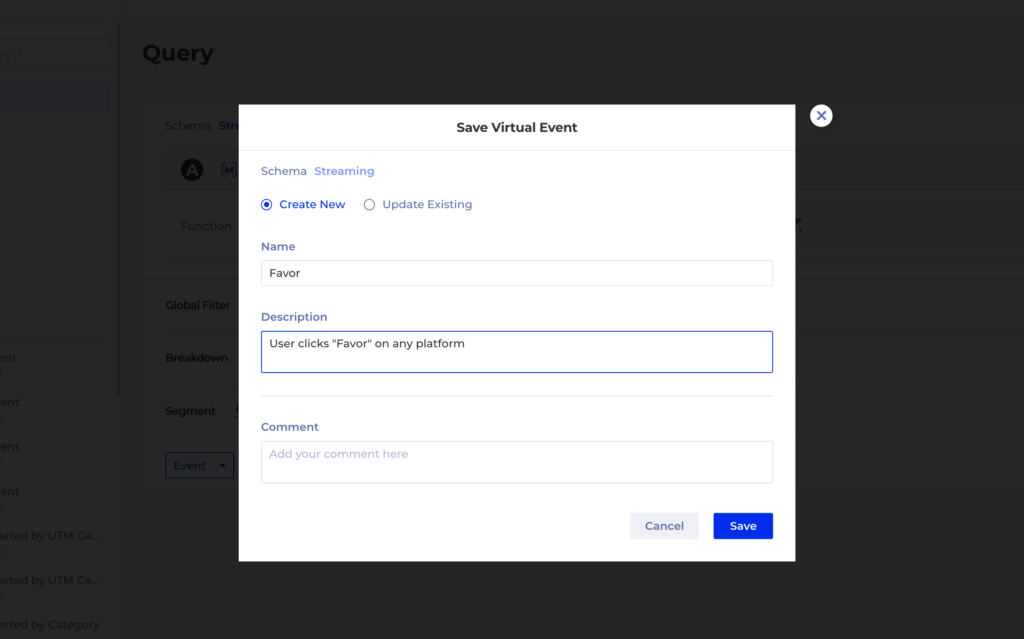
And then the Virtual Event will simply appear in any event drop-down with the rest of the regular events, so you can use it for all types of reports:
4.2 Property name mismatch
Let’s say we have a streaming platform and for all the streaming events we have a property called Stream Type. However, a typo was made when implementing the instrumentation on Android and the property is called Stream type instead. Now, for the purposes of our reports we want to treat these two as one and the same, so that our metrics don’t get skewed.
To fix this in the data warehouse properly we would need to:
- correct the Android instrumentation in a new app version
- go back in our historical data and fix the property name retrospectively
And we still haven’t solved the issue completely – what about all the people who are using older app versions and don’t have the instrumentation fix? They will keep generating data using the inconsistent property name. Turns out a simple typo will be causing us trouble for a long time in our reporting.
There’s 2 solutions which Kubit can provide to help you work around such issues:
- You can create Named Filters using both property names and save them for reuse
- The Kubit team can easily make such configurations as to treat both properties as one and the same
Let’s explore option #1. In this case we have 2 properties which are actually the same – Plan Type and PlanType. So whenever we want to filter by one of them we actually need to filter by both in order to ensure our filter is applied correctly:
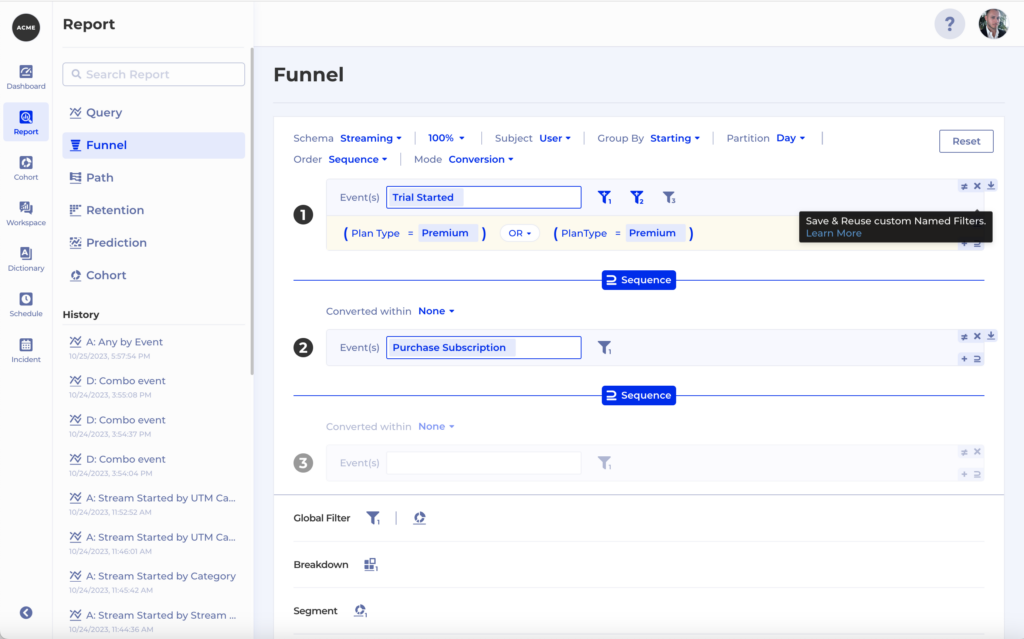
To help prevent mistakes you can then save a Named Filter which others can re-use. Also helps you save time by not having to create the same filter over and over again:
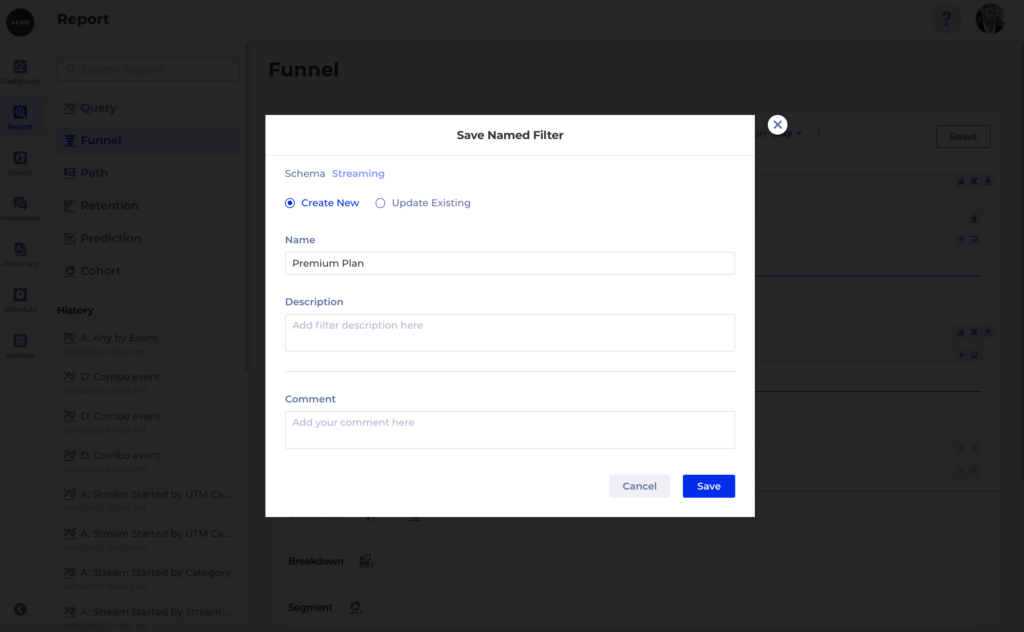
Once the filter is saved you can use it anywhere in Kubit:
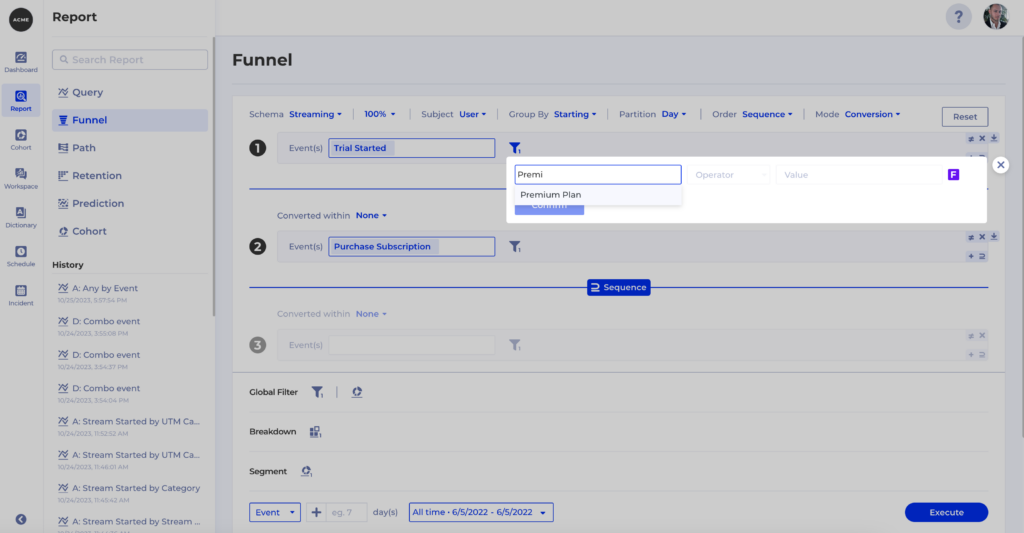
4.3 Property value mismatch
This typically wreaks havoc in our report when we group by that property. For instance, a simple typo in a property value will lead to our report containing 2 groups of the same thing instead of 1 as in the example below:
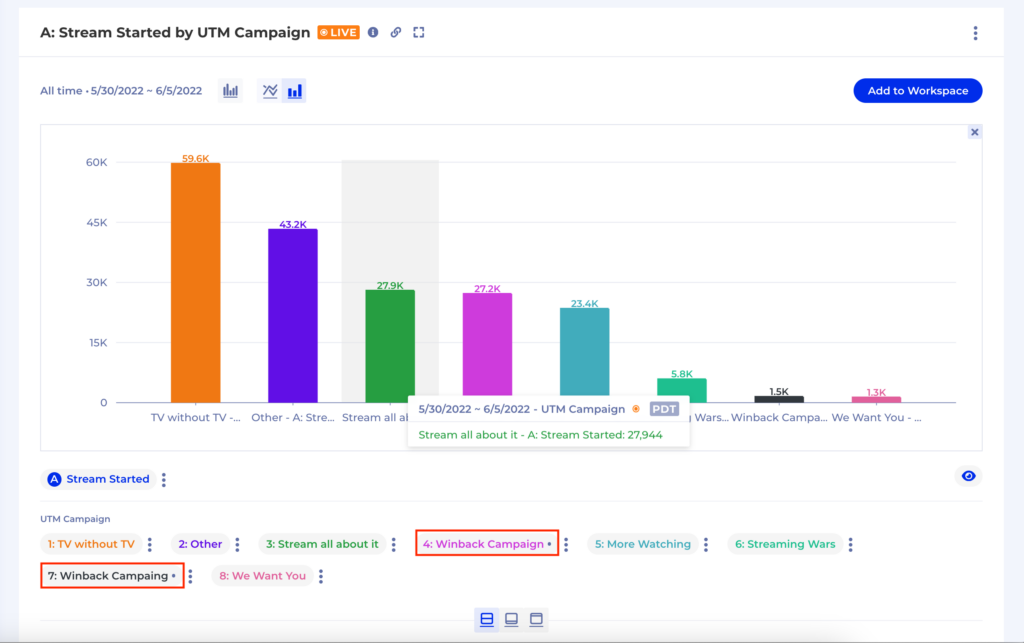
To overcome issues like this on the spot you can use Kubit’s Binning feature:
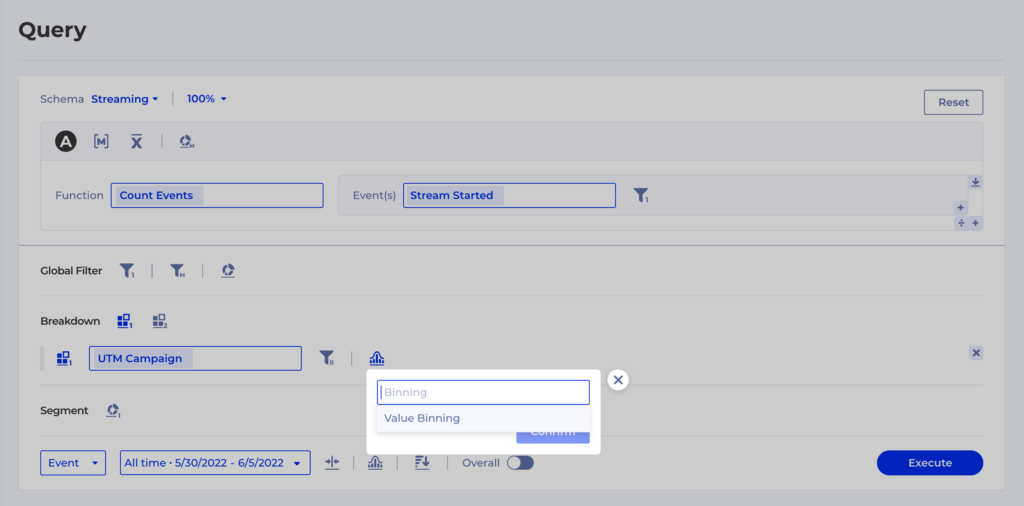
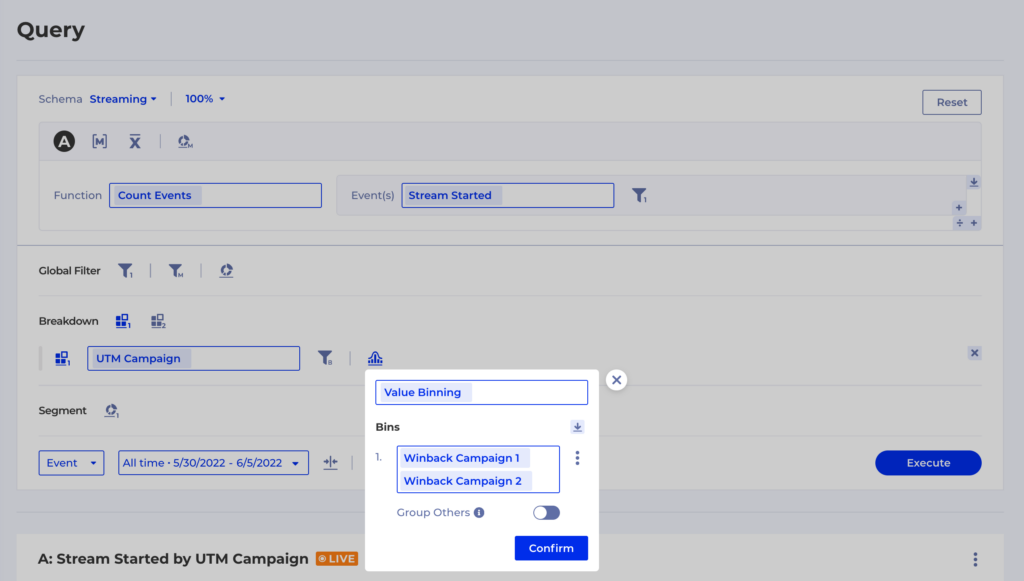
Using the Value Binning option you can define custom Groups – in this case we want to merge back Winback Campaign and Winback Campaing into one group and then we want to leave Group Othersturned off so all the other groups remain as they were:
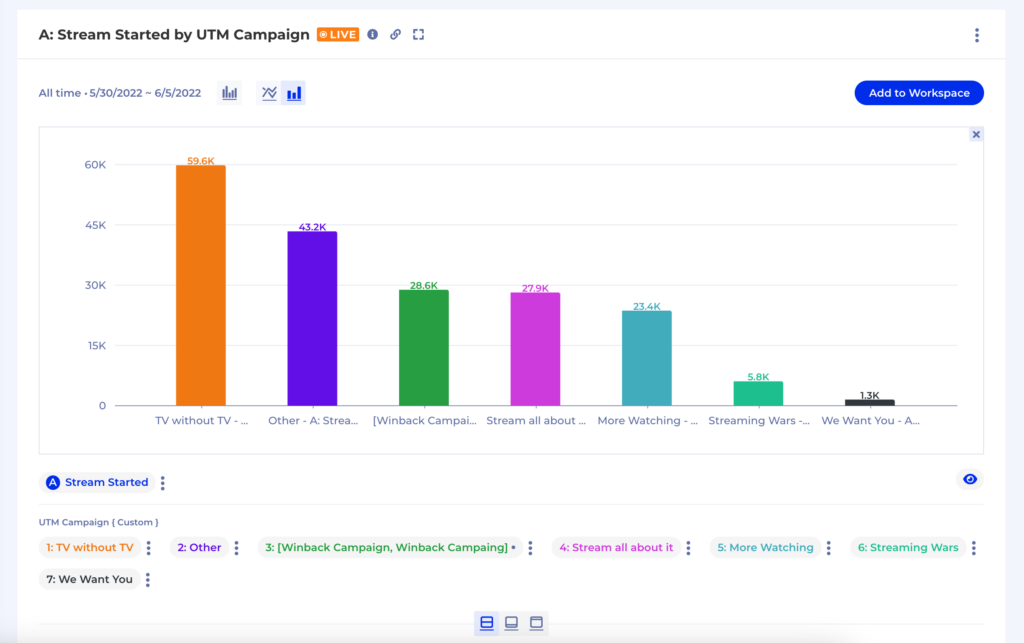
Congratulations, you’ve successfully removed the extra group from your report:
5. Too Much Data
What if our perfect data model contains more event types than we need for our analytical purposes? Or we have an event which is still noisy and in the process of being fixed, so we want to prevent people from relying on it in their reports?
The Dictionary feature in Kubit keeps track of all your terms – Events and Fields coming from the raw data and also concepts defined by you such as Measure and Cohort. Dictionary also allows you to easily disable an event, which means it will no longer be available for selection in any event drop-down in Kubit. All you have to do is go to Dictionary -> Event and then hit Disable from the context menu of the event you want to hide:
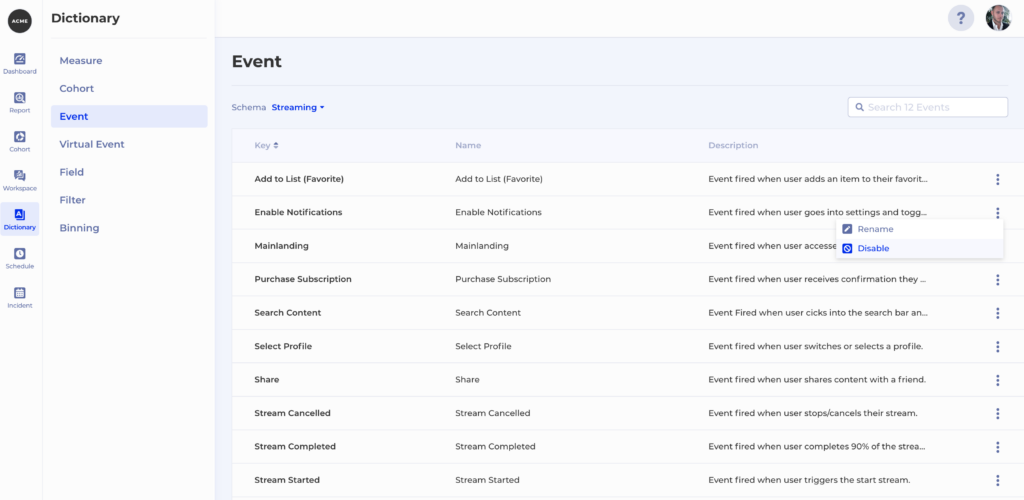
Note that in the case where you are dealing with a noisy event you can easily enable it once the underlying issues with the event generation have been resolved.
Outro
We just explored 5 ways to overcome common data quality issues in Kubit and get to your insights on time. The best part is that all of these solutions are dynamic and the mapping happens at runtime so you can take action immediately. You don’t ever need to invest in complex ETL jobs to update and backfill data. This also gives you the ability to test some hypotheses with real data with live product insights.
At Kubit, we want our customers to have the best possible experience, so please, do let us know what else you would like to get from Kubit to tackle data quality issues!
